
Generating Imagery Programmatically#
One of the largest changes in the AI/ML space in the past 5 years, is the ability of a user to create images from statistical models using different types of input. There have been incredible breakthroughs in the past year alone that defy most expectations, and have caused serious concerns about the viability of art and video production by human hands going forward.
Hopefully, taking a look at where it all started and walking through how it evolved will help us understand what the future might hold; let’s see what we can learn.
A Brief History of Computational Imagery#
“To define what it takes to build an apple pie, first we must define the universe.”
– Carl Sagan, Cosmos
I’m going to try my hardest not to invent the whole universe before I give you the things you came here to read, so I’ll be brief until we get to when AI gets spicy in the 2010s.
Why All This is Important#
Without the advances in technology required to understand how to make and alter images, we wouldn’t have been able to understand them enough to apply our models to the task of image generation.
Timeline#
Manual Digital Art
1960s
 Programmatic imagery first began back in the 1960s, with the creation of Sketchpad, which allowed users to draw on a screen with a light pen.
Programmatic imagery first began back in the 1960s, with the creation of Sketchpad, which allowed users to draw on a screen with a light pen.Mathematical Geometry
1970s
 Later, in the 70s, Benoit Mandelbrot, the "father of fractals", developed the Mandelbrot Set in the late 1970s, which could be used for art and generating images indefinitely based on a mathematical formula.
Later, in the 70s, Benoit Mandelbrot, the "father of fractals", developed the Mandelbrot Set in the late 1970s, which could be used for art and generating images indefinitely based on a mathematical formula.
The first video game system, Atari, featuring hits like "Pong" came out in this decade as well.Commercialization and CGI
1980s
 Computational imagery in the mid 80s had begun to take off; Pixar Animation Studios broke off of LucasFilm and began work on its models that would eventually show up in their first movie in the 90s, Toy Story. Other movies from the decade, but other studios, were heavily modified to include CGI, including Tron and the Star Wars films.
Computational imagery in the mid 80s had begun to take off; Pixar Animation Studios broke off of LucasFilm and began work on its models that would eventually show up in their first movie in the 90s, Toy Story. Other movies from the decade, but other studios, were heavily modified to include CGI, including Tron and the Star Wars films.
Mathematical advances including the original Convolutional Neural Network (CNN), the neocognitron, were discovered and implemented in limited scope.Democratizing Computational Imagery
1990s
 In the 1990s, modifying and working with images was revolutionized by the ability for anyone to buy an Adobe Photoshop license. As a point of interest, professional editing of photos until the advent of Photoshop could cost up to $300 an hour. This software was one of the main contributors for the explosion of digital art and, in my opinion, opened the door for the creation of the training data used for the models we see today.
In the 1990s, modifying and working with images was revolutionized by the ability for anyone to buy an Adobe Photoshop license. As a point of interest, professional editing of photos until the advent of Photoshop could cost up to $300 an hour. This software was one of the main contributors for the explosion of digital art and, in my opinion, opened the door for the creation of the training data used for the models we see today.
Additionally, this was the decade where pioneering techniques of image processing began to circulate amongst the scientific community; Yann LeCun published his paper on backpropagation in CNNs in 1989, and subsequent papers were published in 1990.Getting Ready for Takeoff
2000s
 With the advent of Python 2 in 2000 and the explosion in volume of content on the internet after the Dot Com Bubble, the ecosystems that would enable modern software and machine learning techniques and the dissemination of them began to form. In addition to the sheer volume of data required for modern AI to bloom, there was a boom in interest and availability of general compute power. People were starting to catch on, and it was only a matter of time until people started putting the techniques created in the past 40 years into action.
With the advent of Python 2 in 2000 and the explosion in volume of content on the internet after the Dot Com Bubble, the ecosystems that would enable modern software and machine learning techniques and the dissemination of them began to form. In addition to the sheer volume of data required for modern AI to bloom, there was a boom in interest and availability of general compute power. People were starting to catch on, and it was only a matter of time until people started putting the techniques created in the past 40 years into action.Escape Velocity Achieved
2010s
Programmers began playing with new ideas, specifically the ideas of machine learning and computer vision, that had been painted in previous years. Competitions for computer vision were popping up around the world, one of the most famous turning the world's eye to AI development; ImageNet's Large Scale Visual Recognition Challenge gave way to the creation of AlexNet, one of the first major instances of a CNN trained on a GPU, and paved the way for transfer learning to be implemented.



Frameworks started to show up in alpha and 1.0 versions, SciKit Learn and Apache Spark in 2010, Google's TensorFlow in 2015, Facebook's PyTorch in 2016, and more continued to enter the public eye through open source. Techniques for video processing, image segmentation, classifcation, and some of the first major architectures for generation began to surface.
Architectures of the 2010s#
Generative Adversarial Networks (GANs)#
GANs are a type of neural network architecture that uses two competing networks, the Generator and the Discriminator, to create images different from the initial inputs.
The Generator network tries to create images from a specific input data distribution and will then pass its created outputs to the Discriminator network. The Discriminator will take in real data as well as the input from the Generator and then provide feedback to the Generator; the networks build off of each others’ inputs to each other until they reach convergence, with the Generator able to fool the Discriminator with data it can’t distinguish from the original dataset.
An important thing to note for performance on GANs, one will always beat the other, and then lose to the other temporarily, and then win temporarily, over and over until super latent patterns are being used for comparison. One network needs to be worse than the other to accomplish this.
The use cases for GANs are varied, from Bladerunner style image enhancement, to generating synthetic data usable in other projects, even to creation and modification of art and film, such as deepfakes.



The original paper on GANs is here if you want to read it, or the Wikipedia page.
Variational Autoencoders (VAEs)#
VAEs are a neural architecture that also consists of two networks, this time not in competition, but one to compress data and one to reconstruct it from a probability distribution. The probability distribution is what separates a VAE from a regular Autoencoder. When sampling a probability distribution for reconstruction, the reconstructor can create new data from the inputs that didn’t exist in the original dataset by using different, but similar values.
VAEs are commonly used for image and text generation, data compression and denoising, anomaly detection, and more. There are documented cases of VAEs being used in industry for drug discovery, game development, and market modeling.
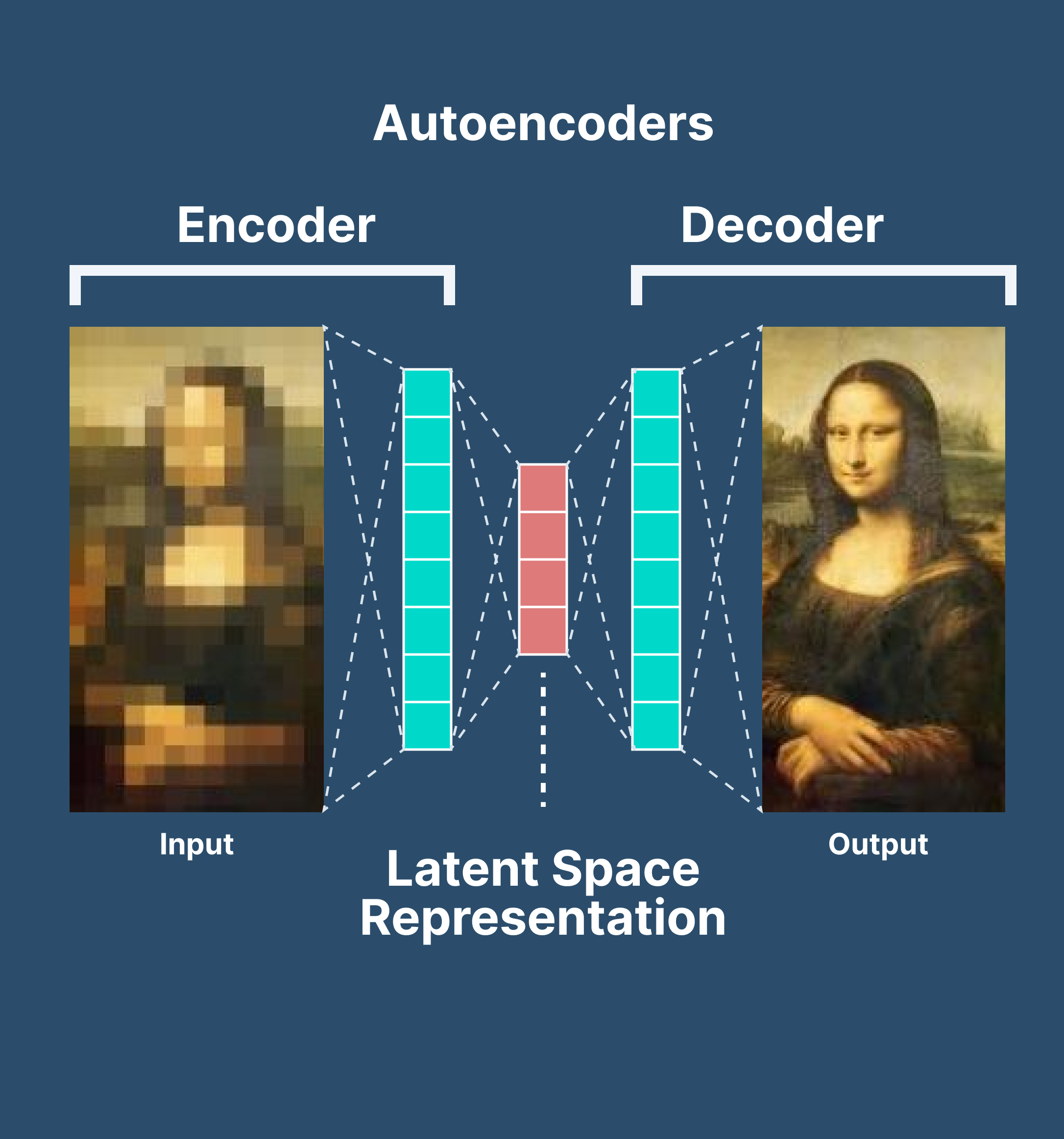
The original paper on VAEs is here if you want to read it, or the Wikipedia page.
Architectures of Today#
In addition to the architectures introduced in the 2010s, which are still valid and in use today, there has been an explosion in the amount of architectures used for image generation models. The ones below are the most prominent at the time of this post’s publishing.
Transformers and LLMs#
Transformer models have been hot on the AI scene since the original paper, Attention is All You Need. In the past couple of years, they’ve actually gone from being used mostly for NLP to expand into the field of image generation.
Transformers now work as text-to-image models, converting text from characters to fully created images, usually by encoding the text, and decoding an image, and utilizing attention heads (the transformer part of the model) to focus on specific parts of the text to use when constructing the image. Not all models are exactly the same in this field, so there may be differences across architectures and applications; some models even use diffusion techniques and transformers architecture, like the DALL-E models.
DALL-E 2 was probably the first major text-to-image model to reach the public eye, and is still available to users in a limited amount for free-of-cost use. The below gallery shows images of the same requests, the first two being DALL-E 2, and the second two from DALL-E 3, accessible through OpenAI’s GPT4 interface.




Diffusion#
Diffusion models are a class of model that create data by diffusing, or adding noise to the data iteratively, and then denoising, which reverses the process and either recovers the original data or generates new data. One of the major ways diffusion models are different from GANs and VAEs are that there is no adversarial process of training with multiple networks.
One of the most famous and most used diffusion models on the market today is Stable Diffusion; it is commonly re-tuned with additional data to change the outputs it is capable of.
 Stability AI is the company that owns Stable Diffusion; check their site or some of their model cards.
Stability AI is the company that owns Stable Diffusion; check their site or some of their model cards.
LORAs and Their Use#
One of the ways many of these diffusion models are re-tuned is by using something called a LORA, or Low Rank Adaptation. LORAs are used to modify a small number of a model’s weights during the fine tuning process to create a specific, controlled effect on the outputs of a model.
LORAs can be used in LLM fine tuning and in tuning diffusion models to create things like a Studio Ghibli style converters or even something like “Gigachad Diffusion”, both pictured below.


Going Beyond “Just” Images#
Images are just the tip of the iceberg here; but there are a number of additional models and tasks being researched in the quasi-image generation space:
- Neural Radiance Fields (NeRFs) - A way to create 3D scenes from 2D images.
- Gaussian Splatter - A semi-related process to NeRFs that creates continuous representations from discrete data, and is being studied to be used in conjunction with radiance fields.
- Video Generation - Models such as OpenAI’s Sora are becoming able to generate entire videos from text.
Opinions on the Future#
Going from what I’ve learned creating this post and doing my own studies, the future looks extremely exciting on the front of image generation.
Models are coming out at an increasingly rapid rate, with new tasks previously thought insurmountable proving to be less difficult than expected, and significant progress happening sometimes week to week.
As less of an image based artist, myself, I can see so many opportunities to use what’s becoming available and I even have used it for assets on this website.
Human Generated Art and Video#
I’ve been asked multiple times by individuals outside the field about the viability of humans continuing to create art in the face of a fast, cheap image and video generator like the models that are being published almost daily.
My thoughts on that are human artists are never going to go out of style.
Human art is the basis of all the training data that has been used for these models up to this point, and I believe that the intrinsic value of human art will never decrease. It will become cheaper, and much harder to sustain being an artist or a screen actor as full time gig, but I do not believe a model will be able to create what a human can in the creative space.
I believe that artists of all sorts will need to incorporate the tools being created now into their workflow, all for different purposes, to continue being able to make a living, but human art will never die so long as humans are here to witness it.
Feedback#
Dicussion#
I’d love to see the comment section fill with thoughts on where you see AI going in art over the next couple years, or if you’re an artist, post how AI has impacted your trade or how you utilize it to make work less tedious and more enjoyable.
Did you like it?#
Leave a comment in the thread on the post!
Did I miss something?#
Also leave a comment on the thread on the post; history is a big topic, and if I missed something critical I’d love to know what it is.