
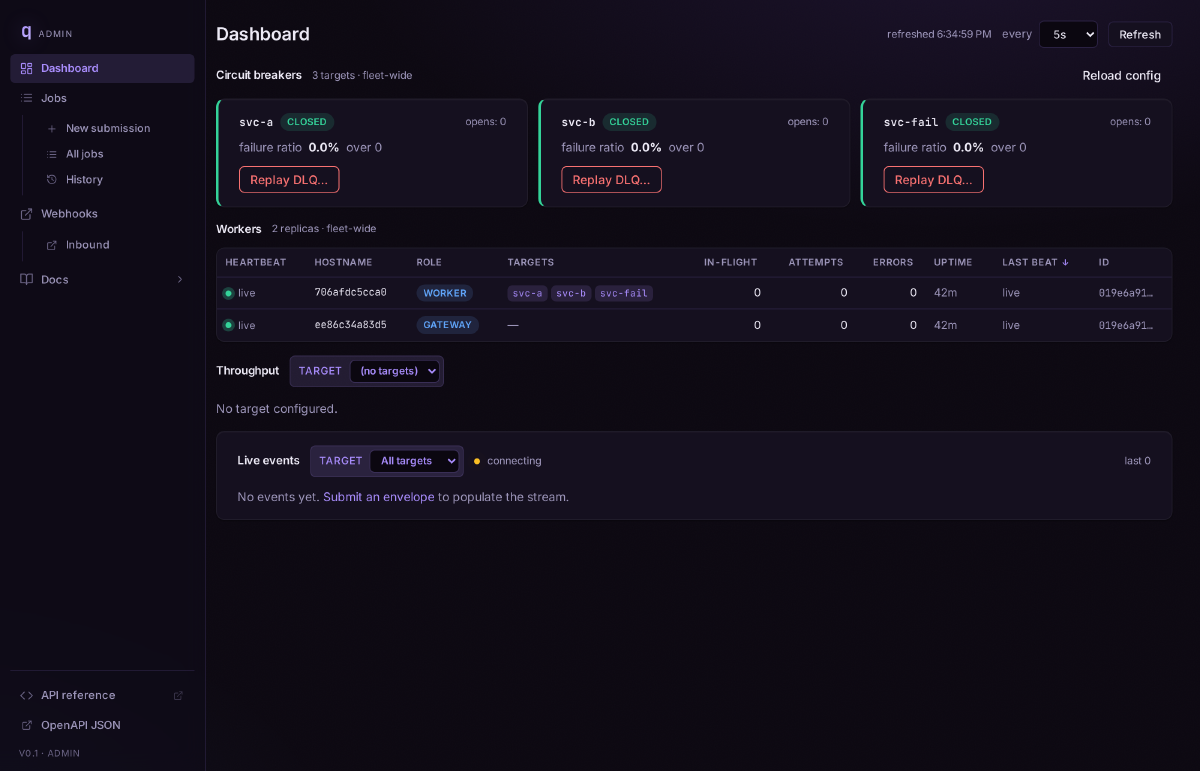

Every service that talks to other services eventually rebuilds the same thing: retries, backoff, circuit breakers, dead-letter handling, idempotency, and an audit trail for “what happened to that request?” Everyone builds it slightly differently and slightly wrong. q is the version that does it once, correctly, as a piece of infrastructure that sits between callers and downstream services.
What it does#
Callers POST /enqueue an envelope — target, method, path, headers, body — and get back a tracked job_id immediately. From there q owns the request: persisting its state, dispatching it to a per-target worker, forwarding it downstream, retrying on failure with a per-target policy, tripping a circuit breaker if the downstream is unhealthy, dead-lettering on exhaustion, and recording every state transition along the way. Job status is queryable for the entire lifecycle.
What makes it interesting#
- Durability is the first promise. Every job and every state transition lands in Postgres before it moves. Crash a gateway, restart a worker, replay the broker — no request is silently dropped, and every one is recoverable to its last known state from Postgres.
- Per-target isolation, end to end. Queues, concurrency caps, retry policies, circuit breakers, DLQs, auth, and retention are all configured per target. A misbehaving downstream can’t degrade traffic to anything else; a noisy neighbor gets its own circuit, not the whole pipeline’s.
- Caller-supplied idempotency. A duplicate
Idempotency-Keyfor the same target returns200 OKwith the originaljob_id; fresh enqueues get202 Accepted. The dedupe boundary is the target, not the global queue, so accidental cross-target collisions don’t merge unrelated requests. - Large payloads spill transparently. Anything over the configured threshold uploads to S3-compatible storage at enqueue time; the job row carries a URI and rehydrates on read. Retention sweeps GC the objects with the rows. Callers see one API; ops gets one byte budget on Postgres.
- Hot-reload with honest boundaries. Retry knobs, retention TTLs, and storage settings apply to running workers without restart. Changes that would invalidate in-flight assumptions — timeouts, circuit config, concurrency, adding or removing a target — explicitly require a rollout, because pretending otherwise would mean lying to callers about the guarantees.
Architecture notes#
flowchart TD caller((Caller)) -->|POST /enqueue| gw[Gateway] gw -->|1 · persist envelope| pg[(Postgres
state of record)] gw -->|2 · publish job| nats{{NATS JetStream
work in flight}} gw -.->|spill if > threshold| s3[(S3-compatible
large payloads)] nats --> w[Worker] w <-->|state · transitions| pg s3 -.->|rehydrate| w w -->|forward
retry · circuit breaker| down([Downstream]) w -.->|dead-letter on exhaustion| dlq{{NATS DLQ stream
per target}}
- The domain layer is pure. No I/O dependencies — types, the state machine, and port traits only. Adapters implement those ports against real systems (HTTP, NATS, Postgres, object storage); the domain doesn’t know which adapter it’s running against. Unit tests run against in-memory fakes; the integration suite wires real adapters together.
- Postgres is the state of record, NATS carries work-in-flight. Two systems with sharply different responsibilities, on purpose. Losing the broker is recoverable from Postgres; losing the database is not. Pretending the broker is durable enough to be a state store would be a lie eventually.
- Read-only secret rotation through a separate watcher. Auth secrets rotate without restarting the workers. Auth scheme changes — bearer vs. basic vs. passthrough — explicitly require a rollout, because they’re structural changes, not credential changes.
- One image, two roles, three deployment shapes. A single binary runs as gateway, worker, or both. The default monolithic topology is the right shape until proven otherwise; splitting into a gateway + per-target worker fleet is an opt-in overlay for teams that need it, not a different chart.
Status#
Personal infrastructure project; source private. Reach out for a demo or to talk through the architecture.
Next Steps#
Thinking about adding an orchestration layer for pipelines or DAG workflows. Will update if that comes to pass! Otherwise:
Reach out on LinkedIn